<aside> ⏰ 本文主要对调度器的整体工作原理进行说明,一个 Pod 是如何进入调度器,如何开启调度,又是如何调度完成,绑定到节点上去的。
</aside>
kube-scheduler 是 kubernetes 的核心组件之一,主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将 Pod 调度到最优的工作节点上面去,从而更加合理、更加充分的利用集群的资源,这也是我们选择使用 kubernetes 一个非常重要的理由。如果一门新的技术不能帮助企业节约成本、提供效率,我相信是很难推进的。
默认情况下,kube-scheduler 提供的默认调度器能够满足我们绝大多数的要求,我们前面和大家接触的示例也基本上用的默认的策略,都可以保证我们的 Pod 可以被分配到资源充足的节点上运行。但是在实际的线上项目中,可能我们自己会比 kubernetes 更加了解我们自己的应用,比如我们希望一个 Pod 只能运行在特定的几个节点上,或者这几个节点只能用来运行特定类型的应用,这就需要我们的调度器能够可控。
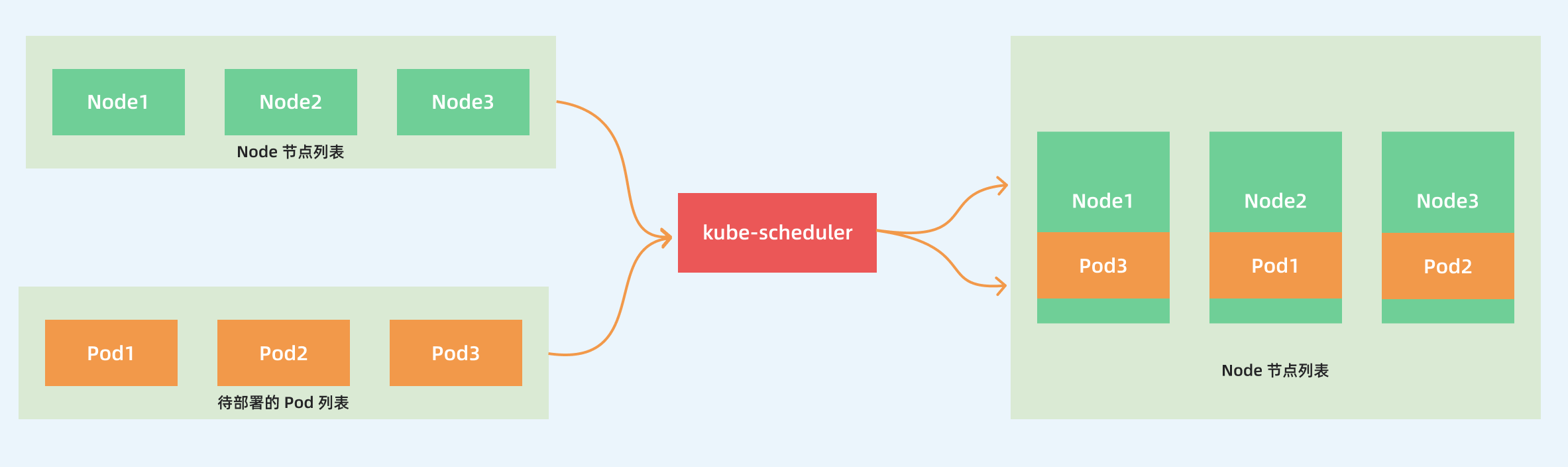
kube-scheduler 的主要作用就是根据特定的调度算法和调度策略将 Pod 调度到合适的 Node 节点上去,是一个独立的二进制程序,启动之后会一直监听 API Server,获取到 PodSpec.NodeName 为空的 Pod,对每个 Pod 都会创建一个 binding。
这个过程在我们看来好像比较简单,但在实际的生产环境中,需要考虑的问题就有很多了:
考虑到实际环境中的各种复杂情况,kubernetes 的调度器采用插件化的形式实现,可以方便用户进行定制或者二次开发,我们可以自定义一个调度器并以插件形式和 kubernetes 进行集成。
kubernetes 调度器的源码位于 kubernetes/pkg/scheduler 中,其中 Scheduler 创建和运行的核心程序,对应的代码在 pkg/scheduler/scheduler.go,如果要查看 kube-scheduler 的入口程序,对应的代码在 cmd/kube-scheduler/scheduler.go。
调度主要分为以下几个部分:
Predicates(过滤)Priorities(打分)