hideBreadcrumbs: true
bottomNavigator: null
title: "서베이 데이터 분석_행복의 요인을 찾아서"
description: "행복(삶의 만족도)에는 어떤 요인이 가장 큰 영향을 미쳤고 변수 간에는 어떤 관계가 있을까요? 하트카운트에 설문 조사 데이터를 넣어 알아보았습니다."
<head>
<link rel="canonical" href="<https://community.heartcount.io/ko/survey/>" />
</head>
관찰(을 통한 행동) 데이터가 넘쳐나는 빅데이터 시대에 왜 관찰하지(Observing Behaviours) 않고 구태의연하게 서베이를 통해 물어 보냐(Asking Questions)고 묻는다면 (그냥 홍시맛이 나서 홍시라 생각했다는 장금이의 답변처럼) “**물어볼 수 있어서 물었다”**고 답해도 괜찮다는 이야기를 해보려고 합니다.
주변에 서베이 데이터를 대체할 수 있는 (직원들의) 행동 데이터가 흔하다 믿고 있는 분들이 서베이 데이터를 가치없다고 폄하하고 있다면 사회과학(Social Science) 진영의 오랜 연구전통과 방법론을 최근 데이터과학(Data Science)과 결합하여 돌파구를 찾아보는 것도 좋겠습니다.
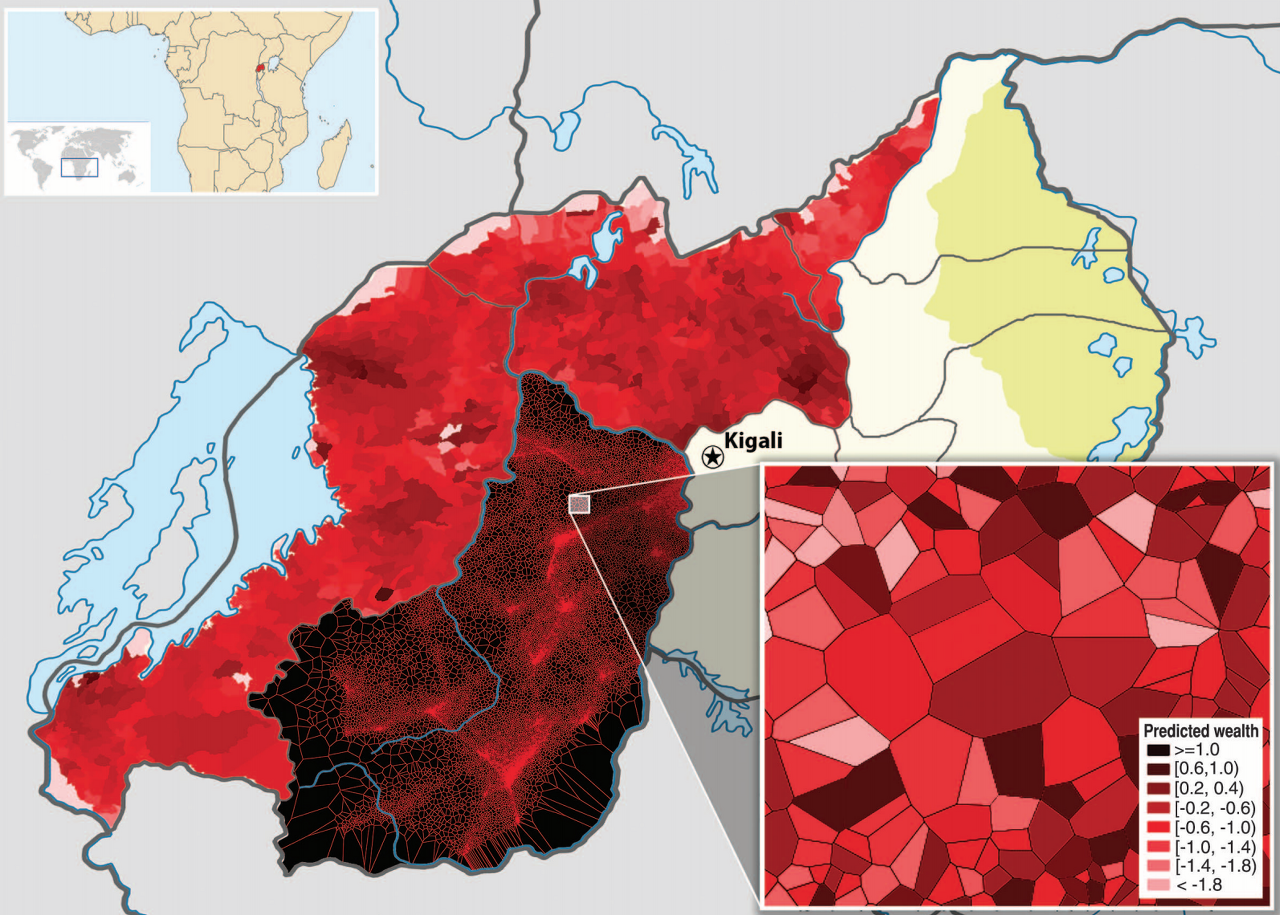
최소한의 노력과 비용으로 르완다 전국의 소득수준 분포를 정확하게 확인하려면 어떻게 해야할까요?
2009년 Joshua Blumenstock(빈곤한 국가나 분쟁 지역에 사는 사람들의 사회적 경제적 처지를 데이터를 통해 설명하는 유익한 프로젝트를 수행하고 있는 UC Berkeley 대학의 조교수)은 이 문제를 달랑 856명에게 전화를 돌려 해결하였습니다.
그 내용을 간단히 요약하면, 르완다 1위 무선통신사업자가 보유한 150만여명 가입자들의 CDR(Call Detail Records; 어디 사는 누가 어디 사는 누구와 얼마 동안 통화했는지를 기록한 로그) 데이터와 전화 설문을 통해 확인한 소득/경제 수준에 대한 데이터를 결합하여 CDR 정보로 소득 수준을 예측하는 모형을 만들었던 것이죠.
서베이를 통해 확인한 850여명의 소득/경제수준(Y)과 이들의 모바일 전화통화 내역(X; CDR)을 기계학습 알고리즘을 사용하여 학습한 후, 예측모형을 만들어서 CDR 정보(X)만으로 소득/경제 수준(Y)을 예측하도록 했습니다.
사회과학 연구 방법인 서베이와 데이터과학을 결합하여 저렴하고 빠르게 유용한 정보를 얻은 훌륭한 사례입니다.
https://img1.daumcdn.net/thumb/R1280x0.fpng/?fname=http://t1.daumcdn.net/brunch/service/user/cqBJ/image/kFHY00ziotGFrDo4Bme_X0LG5Cg.png
Call Record로 작성한 르완다 빈부 지도
참고) 해당 프로젝트에 대한 보다 자세한 내용:
http://science.sciencemag.org/content/sci/350/6264/1073.full.pdf
초파리를 연구하는 사람들은 초파리를 더 잘 이해하기 위해서 초파리의 행동을 관찰하는 수밖에 없겠죠.
{kind=link}