<aside> 🤡 本文主要介绍 client-go 的 Informer 和 Cache
</aside>
前面我们在使用 Clientset 的时候了解到我们可以使用 Clientset 来获取所有的原生资源对象,那么如果我们想要去一直获取集群的资源对象数据呢?岂不是需要用一个轮询去不断执行 List() 操作?这显然是不合理的,实际上除了常用的 CRUD 操作之外,我们还可以进行 Watch 操作,可以监听资源对象的增、删、改、查操作,这样我们就可以根据自己的业务逻辑去处理这些数据了。
Watch 通过一个 event 接口监听对象的所有变化(添加、删除、更新):
// staging/src/k8s.io/apimachinery/pkg/watch/watch.go
// Interface 可以被任何知道如何 watch 和通知变化的对象实现
type Interface interface {
// Stops watching. Will close the channel returned by ResultChan(). Releases
// any resources used by the watch.
Stop()
// Returns a chan which will receive all the events. If an error occurs
// or Stop() is called, this channel will be closed, in which case the
// watch should be completely cleaned up.
ResultChan() <-chan Event
}
watch 接口的 ResultChan 方法会返回如下几种事件:
// staging/src/k8s.io/apimachinery/pkg/watch/watch.go
// EventType 定义可能的事件类型
type EventType string
const (
Added EventType = "ADDED"
Modified EventType = "MODIFIED"
Deleted EventType = "DELETED"
Bookmark EventType = "BOOKMARK"
Error EventType = "ERROR"
DefaultChanSize int32 = 100
)
// Event represents a single event to a watched resource.
// +k8s:deepcopy-gen=true
type Event struct {
Type EventType
// Object is:
// * If Type is Added or Modified: the new state of the object.
// * If Type is Deleted: the state of the object immediately before deletion.
// * If Type is Bookmark: the object (instance of a type being watched) where
// only ResourceVersion field is set. On successful restart of watch from a
// bookmark resourceVersion, client is guaranteed to not get repeat event
// nor miss any events.
// * If Type is Error: *api.Status is recommended; other types may make sense
// depending on context.
Object runtime.Object
}
这个接口虽然我们可以直接去使用,但是实际上并不建议这样使用,因为往往由于集群中的资源较多,我们需要自己在客户端去维护一套缓存,而这个维护成本也是非常大的,为此 client-go 也提供了自己的实现机制,那就是 Informers。Informers 是这个事件接口和带索引查找功能的内存缓存的组合,这样也是目前最常用的用法。Informers 第一次被调用的时候会首先在客户端调用 List 来获取全量的对象集合,然后通过 Watch 来获取增量的对象更新缓存。
一个控制器每次需要获取对象的时候都要访问 APIServer,这会给系统带来很高的负载,Informers 的内存缓存就是来解决这个问题的,此外 Informers 还可以几乎实时的监控对象的变化,而不需要轮询请求,这样就可以保证客户端的缓存数据和服务端的数据一致,就可以大大降低 APIServer 的压力了。
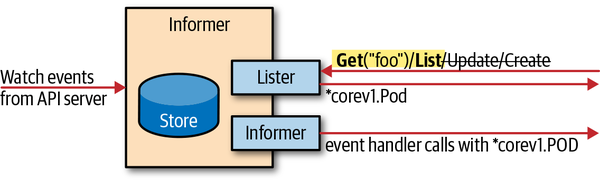
Informers
如上图展示了 Informer 的基本处理流程:
此外 Informers 也有错误处理方式,当长期运行的 watch 连接中断时,它们会尝试使用另一个 watch 请求来恢复连接,在不丢失任何事件的情况下恢复事件流。如果中断的时间较长,而且 APIServer 丢失了事件(etcd 在新的 watch 请求成功之前从数据库中清除了这些事件),那么 Informers 就会重新 List 全量数据。
而且在重新 List 全量操作的时候还可以配置一个重新同步的周期参数,用于协调内存缓存数据和业务逻辑的数据一致性,每次过了该周期后,注册的事件处理程序就将被所有的对象调用,通常这个周期参数以分为单位,比如10分钟或者30分钟。
注意:重新同步是纯内存操作,不会触发对服务器的调用。
Informers 的这些高级特性以及超强的鲁棒性,都足以让我们不去直接使用客户端的 Watch() 方法来处理自己的业务逻辑,而且在 Kubernetes 中也有很多地方都有使用到 Informers。但是在使用 Informers 的时候,通常每个 GroupVersionResource(GVR)只实例化一个 Informers,但是有时候我们在一个应用中往往有使用多种资源对象的需求,这个时候为了方便共享 Informers,我们可以通过使用共享 Informer 工厂来实例化一个 Informer。