cleanUrl: "relative-positional-encoding"
description: "Relative positional encoding에 대해 정리합니다."
[논문리뷰] Relative Position Representations in Transformer
import math
import torch
def _relative_position_bucket(relative_position, bidirectional=True, num_buckets=32, max_distance=128):
relative_buckets = 0
if bidirectional:
num_buckets //= 2
relative_buckets += (relative_position > 0).to(torch.long) * num_buckets
relative_position = torch.abs(relative_position)
else:
relative_position = -torch.min(relative_position, torch.zeros_like(relative_position))
# now relative_position is in the range [0, inf)
# half of the buckets are for exact increments in positions
max_exact = num_buckets // 2
is_small = relative_position < max_exact
# The other half of the buckets are for logarithmically bigger bins in positions up to max_distance
relative_postion_if_large = max_exact + (
torch.log(relative_position.float() / max_exact)
/ math.log(max_distance / max_exact)
* (num_buckets - max_exact)
).to(torch.long)
relative_postion_if_large = torch.min(
relative_postion_if_large, torch.full_like(relative_postion_if_large, num_buckets - 1)
)
relative_buckets += torch.where(is_small, relative_position, relative_postion_if_large)
return relative_buckets
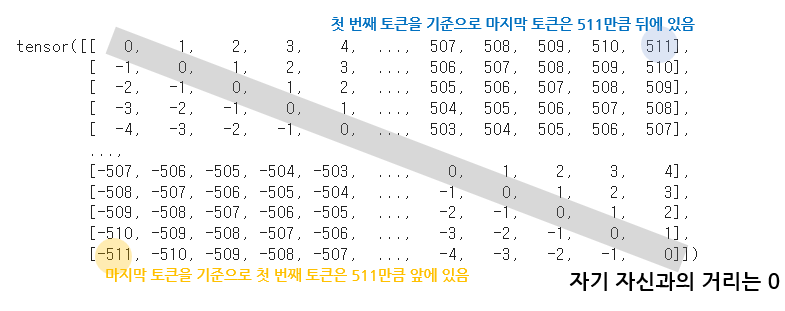
인풋 시퀀스 512인 문장에 대해 Self-attention 상황을 가정하면, relative position은 다음과 같이 구할 수 있다.
이제 이 relative position을 _relative_position_bucket에 대입하면 상대적인 거리에 따른 버킷 값을 얻을 수 있다.

이 버킷 값은 scalar로 임베딩 하여 attention score을 구할 때 logit에 더해져 위치 정보를 반영하게 된다.
(가까운 거리에 있는 토큰이 더 큰 가중치를 받을 수 있게 학습되지 않을까?)